Chapter 7 Course Exercises
7.1 The issues of data synthesis
7.1.1 Greenland’s size
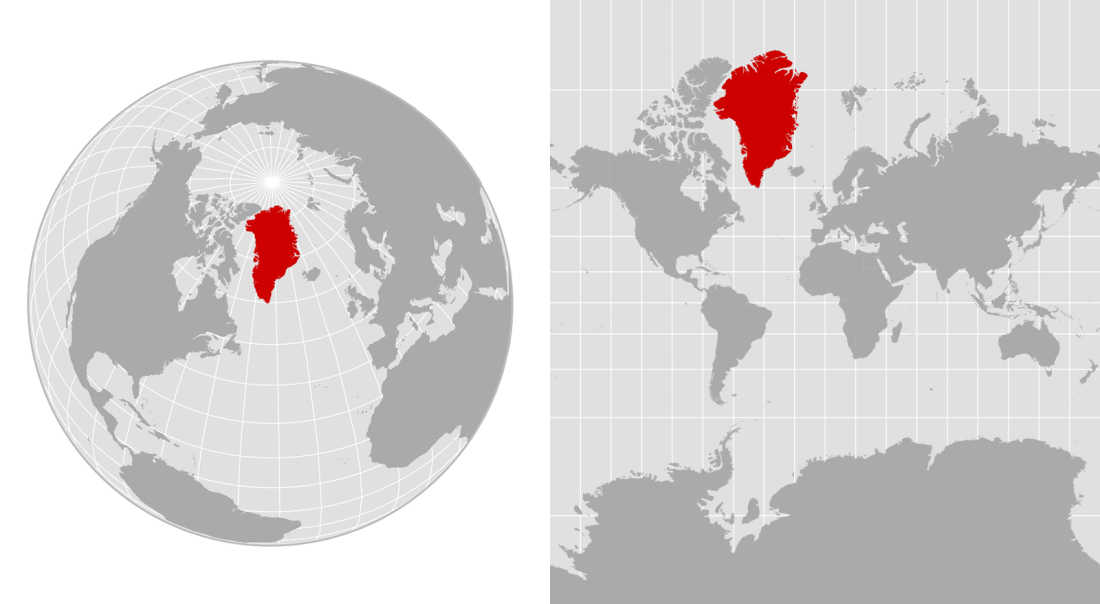
Figure 7.1: The left map shows an orthographic projection, emulating a globe. The right map is a Mercator projection, which exaggerates the sizes of landmasses, including Greenland. Alyson Hurt / NPR
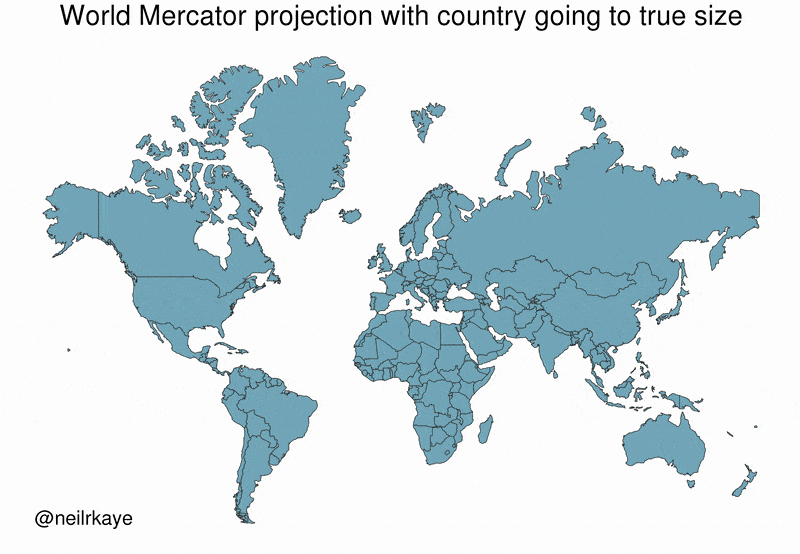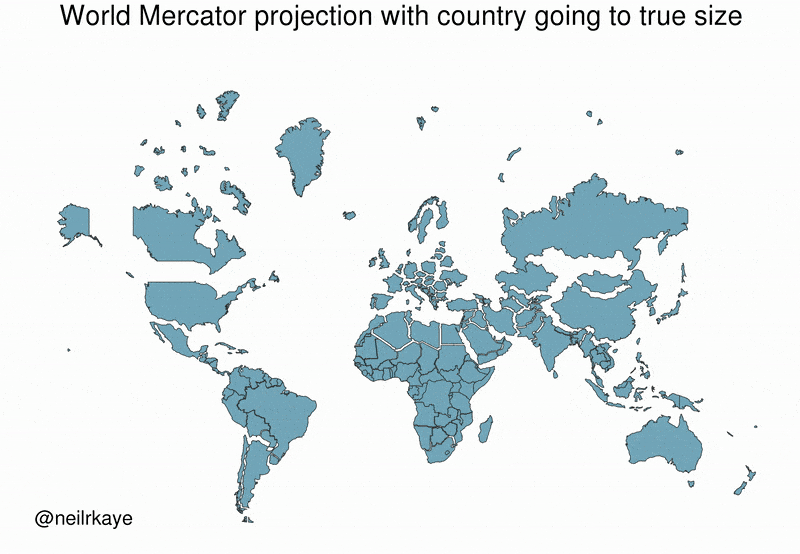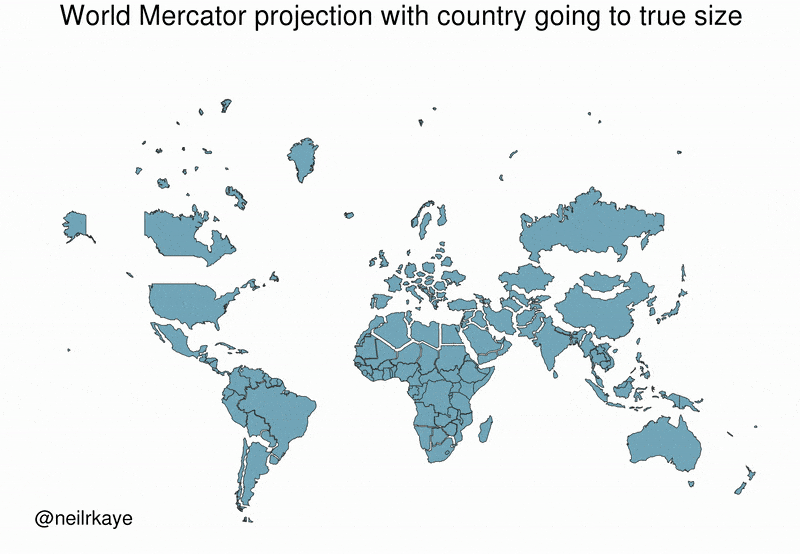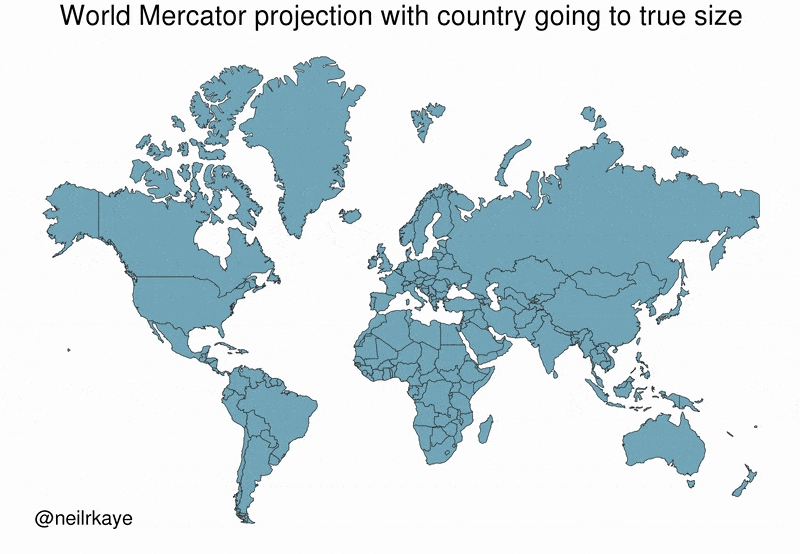
Many people believe that Greenland is comparable in size to Africa or larger than South America. This belief is widespread in textbooks, news media, and online discussions. This belief is reinforced by commonly used world maps based on the Mercator projection, where Greenland appears vastly larger than it truly is.
In reality, Greenland’s surface area is approximately 2.1 million km², while Africa’s is about 30 million km². The apparent similarity in size is not due to incorrect measurements, but to a systematic distortion introduced by map projection and visual synthesis. In Fact, Greenland’s size is comparable to countries like Saudi Arabia or Mexico.
This example illustrates how correct data, when transformed, aggregated, or visualised improperly, can generate persistent and intuitive false beliefs. Distortions from data synthetisation may be intentional or accidental, yet their effects are powerful, especially when visual representations are treated as neutral or self-explanatory.
Answer the following questions:
- Give one example in data science where aggregation or visualisation can similarly mislead interpretation without involving false data.
- Explain why this example illustrates a problem of data synthesis and representation rather than incorrect data collection.
- Briefly explain how similar distortions in data science can contribute to biased narratives, echo chambers, or misguided policy decisions.
- When does data stop describing reality and start constructing it?
How to approach the answers:
This exercise is designed to help you reason about distortion introduced by data synthesis and representation, rather than errors in measurement or data collection. The goal is not to test geographical knowledge, but to see how true data can still lead to false beliefs once transformed or visualised.
When approaching the first question, focus on identifying an example where:
- the underlying data are correct,
- yet aggregation, scaling, or visual encoding changes how the data are perceived.
Typical candidates include averages hiding variability, misleading axes in charts, heatmaps without normalization, or global indicators masking regional disparities. The key is to show that nothing is fabricated, but interpretation is nonetheless skewed.
For the second question, clearly separate data collection from data representation. Ask yourself:
- Were the original quantities measured accurately?
- At what step does distortion enter?
Your explanation should make clear that the problem arises after data collection, during transformation, aggregation, or visualisation choices. This reinforces the idea that epistemic failure often occurs downstream from measurement.
The third question invites you to connect epistemic distortion to social and ethical consequences. When thinking about biased narratives or echo chambers, consider how repeated exposure to the same distorted representation can:
- legitimise certain interpretations,
- or marginalise alternative perspectives.
You are not asked for a detailed sociological theory, but for a plausible mechanism linking representation to belief and action.
The final question is intentionally reflective and normative. There is no single correct answer. Instead, you should:
- articulate a criterion or threshold (e.g. scale, repetition, authority, policy use),
- explain when representations cease to be descriptive tools and become world-shaping constructs.
This question tests your ability to integrate epistemology, data practice, and ethics, rather than recall factual content.
Overall, approach this exercise by keeping in mind that data visualisations are not neutral windows onto reality. They are models and syntheses that highlight some aspects while obscuring others, and this selective emphasis is precisely where both insight and distortion originate.
7.2 Learning from History
These exercises explore how knowledge is produced, interpreted, and acted upon under conditions of uncertainty by examining historical cases that mirror core problems in modern data science.
Across medicine, public health, history, and environmental management, the cases show how evidence is shaped by proxies, data-generating processes, missing controls, ethical constraints, and high-stakes decision-making. Rather than focusing on technical calculation, the questions invite you to reflect on reasoning: what data actually measure, what they fail to capture, how comparisons substitute for experiments, and why correct conclusions can sometimes emerge from weak or incomplete evidence. Together, the cases illustrate that epistemic judgement, not just data volume or statistical fit, is central to responsible inference and action
7.2.1 Al-Razi and Hospital Location

In the 10th century, the Persian physician Al-Razi was tasked with selecting the most suitable location for a new hospital in Baghdad, a large and densely populated city. At the time, medical knowledge relied heavily on authority, tradition, and humoral theories, and there were no instruments to measure air quality, pollution, or disease risk.
Rather than choosing a location based on prestige, custom, or anecdotal reputation, Al-Razi sought a method that relied on observable differences across districts. He placed pieces of raw meat in several parts of the city and monitored how quickly they decayed. His reasoning was indirect: faster decay suggested environmental conditions that might also promote illness, while slower decay suggested cleaner air.
This approach did not involve experimental control, randomisation, or a causal theory of disease transmission. He could not isolate variables such as temperature, insects, or humidity, nor could he test alternative explanations. However, his method represented a deliberate attempt to compare environments systematically using a proxy rather than speculation, authority, or superstition.
Questions
- What role does the meat play in Al-Razi’s reasoning?
- Is this an example of direct measurement of air quality?
- What experimental control is missing in this method? Name one.
- Why does the inference remain uncertain even if the method is systematic?
- Give a modern data-science analogy to Al-Razi’s approach.
How to approach the answers:
- Find the epistemic role of a proxy and distinguish it from direct measurement.
- Think about what is being inferred vs. what is observed.
- Reflect on missing controls (confounders, standardisation, replication).
- Emphasise why systematic comparison reduces arbitrariness but does not eliminate uncertainty.
- For the analogy, map proxy to target in modern data science (e.g., indirect indicators).
7.2.2 Ibn Sina and Medical Evidence

In the 11th century, Ibn Sina (Avicenna) reflected critically on medical practice. He observed that physicians often inferred the effectiveness of treatments after witnessing a few apparent recoveries, without considering alternative explanations.
He warned that recovery could result from natural healing, coincidence, or concurrent interventions. He argued that without systematic comparison and repetition under similar conditions, physicians risked mistaking chance or background processes for causal effects.
Although formal experimental methods were not yet developed, Ibn Sina articulated a core insight of modern experimental reasoning: isolated success stories are epistemically weak. Reliable knowledge requires distinguishing treatment effects from background variation.
Questions
- What epistemic problem does Ibn Sina identify in relying on individual treatment successes?
- Why is the argument “the patient recovered after treatment, therefore the treatment works” problematic?
- What core principle of experimental control is Ibn Sina implicitly advocating?
- Give one example of how Ibn Sina’s critique applies to modern data science.
How to approach the answers:
- Focus on post hoc reasoning and confounding.
- Identify the difference between correlation, coincidence, and causation.
- Find modern analogies like baselines, control groups, or validation.
- Use a contemporary example involving misleading performance claims.
7.2.3 Florence Nightingale and Military Mortality

Figure 7.2: Florence Nightingale’s 1858 ‘Rose Diagram’. It uses color-coded wedges to show that more soldiers died from preventable infections (blue) than from battlefield wounds (red). By comparing mortality before and after sanitary reforms, she visually proved that basic hygiene and ventilation drastically reduced death rates, transforming military healthcare forever.
During the Crimean War in the 1850s, Florence Nightingale confronted widespread assumptions about military deaths. High mortality among soldiers was often attributed directly to battle injuries, reinforcing the belief that little could be done beyond improving combat medicine.
Nightingale collected detailed hospital records and noticed that most deaths occurred away from the battlefield. Rather than relying on total death counts, she reorganised the data by cause of death and time period. She then compared mortality patterns before and after sanitation reforms, using visualisations to communicate her findings.
Although Nightingale could not run controlled experiments or randomise conditions, she approximated control through structured comparison. Her work demonstrated how careful aggregation and disaggregation of observational data could reveal patterns that raw numbers concealed, and her analysis directly informed policy changes that saved lives.
Questions
- Why were raw mortality numbers insufficient to support her conclusions?
- What form of experimental control was approximated in Nightingale’s analysis?
- What statistical issue would occur if deaths were not disaggregated by cause?
- Why was Nightingale’s use of data ethically significant?
How to approach the answers:
- Contrast raw counts with structured comparisons.
- Identify what was being held approximately constant across time periods.
- Consider aggregation bias and loss of explanatory resolution.
- Link ethics to prevention capacity, responsibility, and policy impact.
7.2.4 The Collapse of Angkor

Figure 7.3: Facade of Angkor Wat, a drawing by Henri Mouhot (1860)
When French explorer Henri Mouhot encountered Angkor in the 19th century, he interpreted its overgrown monuments as evidence of sudden civilisational collapse. This interpretation relied heavily on visible ruins as proxies for societal vitality.
Later historical accounts and modern remote sensing revealed a different picture: Angkor declined gradually due to climatic stress and infrastructural strain, not sudden decay or invasion. Monument survival turned out to be a misleading proxy for social complexity and continuity.
Questions
- Identify Mouhot’s main proxy and why it is epistemically risky.
- Explain why this is not a case where experimental control is feasible, and what “control” can mean instead.
- What statistical/causal error occurs if we infer societal vitality from monument survival alone?
- State one ethical risk of colonial knowledge production in interpreting Angkor’s past.
- Propose a data-science analogue where a convenient proxy drives a wrong narrative, and name one mitigation.
How to approach the answers:
- Identify proxy misuse and construct validity.
- Explain non-experimental forms of control (triangulation, comparison).
- Triangulation means: Do different ways of measuring or analysing the same phenomenon point to a similar conclusion?
- Link epistemic error to narrative bias.
- Include ethical dimensions of power and representation.
7.2.5 Goldziher: From Textual Corpora to Historical Claims

In the late nineteenth century, Ignaz Goldziher studied large corpora of Islamic legal and religious texts. Earlier scholars treated these texts as direct historical observations, assuming that many similar reports implied factual accuracy about early Islamic history.
Goldziher challenged this view by analysing how such texts were produced. He argued that legal debates, institutional incentives, and educational transmission shaped what texts were written, preserved, and repeated. As a result, strong regularities could emerge even when the texts were not direct measurements of the historical events they purported to describe.
Goldziher’s insight was not that the data were useless, but that they measured something different from what researchers often assumed. This distinction between data generation and target phenomenon is central to modern data science.
Questions
- What is the core data-science error in treating these texts as direct observations of early historical events? Hint: The target variable here is “early historical events”, and the observed variable “texts produced by later institutions”.
- Explain how a shared generative process can produce strong statistical patterns without corresponding to the target phenomenon.
- Why can increasing dataset size increase confidence in the wrong conclusion in this case?
- Why is it ethically important, in data-driven research, to state clearly what a dataset does and does not measure?
- Give a modern data-science example where data accurately reflects a process but is commonly misinterpreted as measuring a different target.
How to approach the answers:
- Explicitly distinguish observed variables from target constructs.
- Use the idea of generative processes and feedback loops.
- Explain why more data can amplify bias rather than correct it.
- Link ethical responsibility to transparency and misuse prevention.
7.2.6 Wu Lien-teh and the Manchurian Plague

Figure 7.4: Dr Wu Lien-Teh working in his laboratory in Harbin, China, 1911
In the early 1910s, during a plague outbreak in Manchuria, prevailing medical theories emphasised flea-borne transmission. Wu Lien-teh observed rapid spread among people with close contact, including medical staff, suggesting airborne transmission.
Without experimental confirmation or microbiological proof, Wu recommended face masks, quarantine, and burial reforms. These measures were controversial but likely contributed to controlling the outbreak.
The case exemplifies abductive reasoning under severe time pressure and highlights decision-making when experimental control is impossible.
Questions
- Why was experimental confirmation impossible in this case?
- Why was this inference epistemically risky?
- Why would waiting for stronger statistical evidence be problematic?
- What lesson does this case provide for data science in crisis situations?
How to approach the answers:
- Emphasise constraints of time, ethics, and feasibility.
- Identify uncertainty and alternative explanations.
- Discuss asymmetric costs of delay.
- Generalise to modern crisis analytics and precautionary action.
7.2.7 Janet Lane-Claypon and Breast Cancer Research

In the early 20th century, Janet Lane-Claypon investigated possible causes of breast cancer. Many suspected factors were common among affected women, but this alone did not establish causation.
She introduced a systematic comparison between women with breast cancer and women without it. By examining how frequently exposures appeared in each group, she showed that some seemingly important factors were actually common in the general population.
This comparative approach marked an early form of case-control reasoning and laid the groundwork for modern epidemiology, allowing researchers to distinguish coincidence from potential causal influence.
Questions
- Why were common exposures alone insufficient to identify causes of cancer?
- What methodological innovation distinguishes Lane-Claypon’s approach?
- How does this help avoiding misleading conclusions?
- What kind of causal reasoning becomes possible once this innovation is introduced?
- Why is this comparative approach ethically preferable to other types of experimentation?
How to approach the answers:
- Emphasise base rates and comparison groups.
- Identify the methodological shift from description to inference.
- Connect comparison to counterfactual reasoning.
- Discuss ethical constraints in medical research.
7.2.8 Terranova, the Northern Cod Collapse
From the late 1970s to the early 1990s, Canadian regulators relied on stock-assessment models to manage the Northern cod fishery. Indicators such as catch-per-unit-effort suggested stability, even as cod populations declined.
Industrial fishing fleets increasingly concentrated in remaining high-density areas, masking broader collapse. Models remained statistically well-fit, but their assumptions failed under ecological change. When the collapse became undeniable, the resulting moratorium caused widespread social and economic harm.
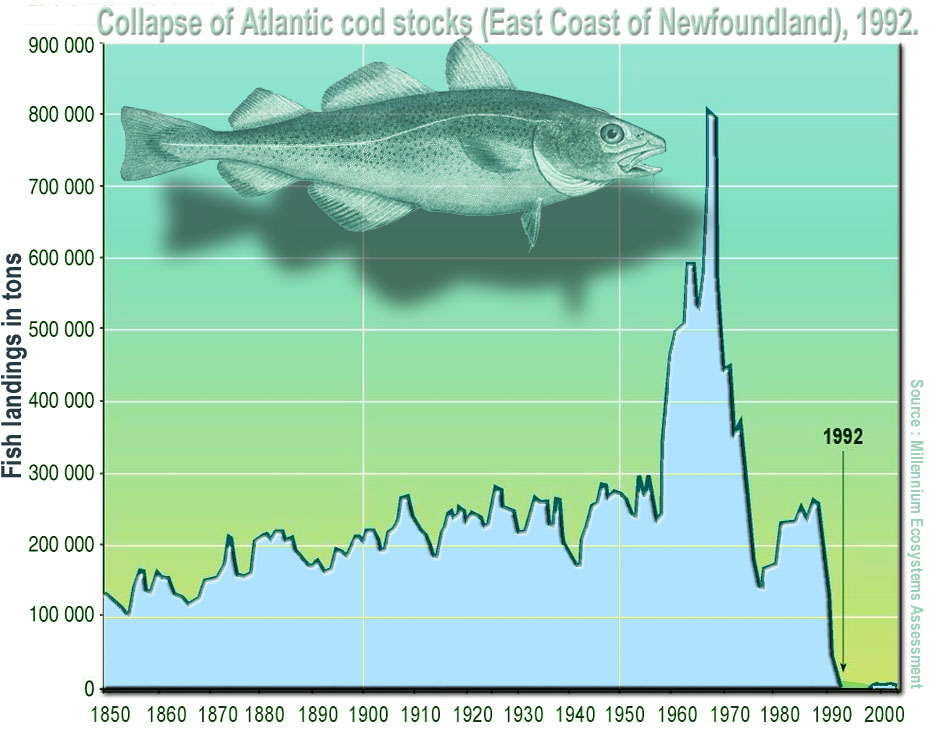
Figure 7.5: Collapse of Atlantic cod stocks off Newfoundland (1992): Offshore trawling since the 1950s drove catches up but biomass down, and international and national quotas failed to stop the decline.
Questions
- Explain how aggregation across space can hide collapse in sub-populations (name the general phenomenon).
- Give one experimental control substitute that regulators could have used.
- Why can a model be statistically well-fit yet epistemically unreliable here?
- What non-epistemic values were in tension when setting quotas (name two)?
How to approach the answers:
- Identify aggregation bias or Simpson-like effects.
- Think of monitoring designs as substitutes for experiments.
- Separate goodness-of-fit from validity of assumptions.
- Name economic, social, or political values explicitly.
7.2.9 Li Wenliang and Early COVID-19 Signals

In December 2019, Li Wenliang, an ophthalmologist in Wuhan, noticed several patients with unusual pneumonia symptoms resembling earlier SARS cases. At that stage, the number of cases was very small, no pathogen had been identified, and no epidemiological studies were available.
From a statistical perspective, the evidence was weak and noisy; from an experimental perspective, no controlled interventions were possible. Nonetheless, Li warned colleagues to take precautions, prioritising potential harm over evidential certainty.
In hindsight, his warning proved correct. The case highlights the tension between epistemic standards and ethical responsibility under uncertainty.
Questions
- Why was it impossible, at the time Li raised concerns, to obtain the kind of evidence normally required for strong causal or statistical inference?
- Why did the available data fail to meet standard criteria for statistical reliability, despite later turning out to be correct?
- What epistemic risk exists in waiting for stronger evidence in situations like this?
- Why does this case raise an ethical duty to warn even when evidence is incomplete?
- What does this case teach about decision-making under uncertainty in high-stakes data-driven systems?
How to approach the answers:
- Contrast ideal evidence with available evidence.
- Explain retrospective validation vs prospective uncertainty.
- Identify asymmetric risks (false alarms vs delayed action).
- Link ethics to precaution and responsibility.